
|
抗體開發特輯:如何解決質體不純的問題?
抗體簡介
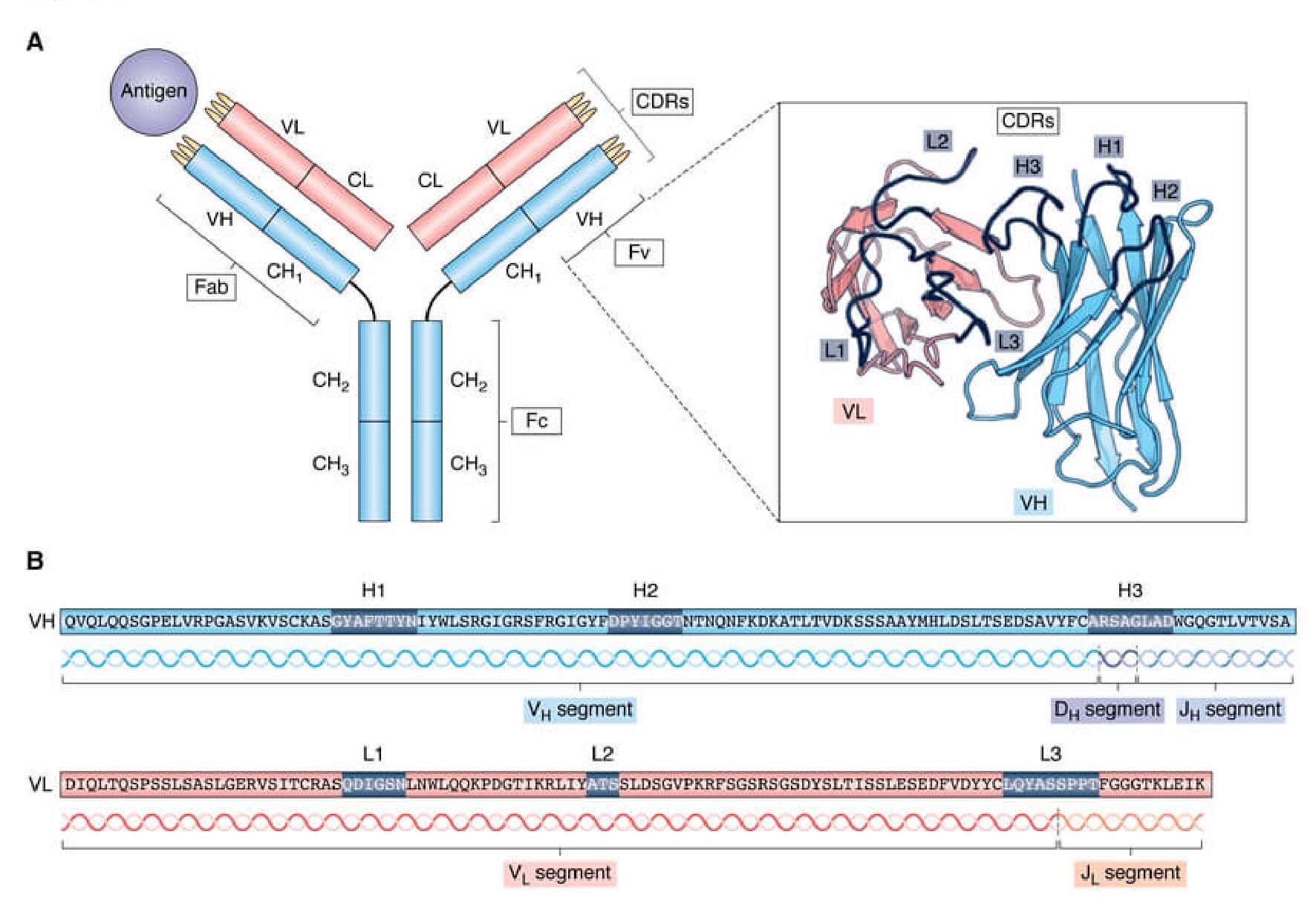
圖源:Marks, Claire, and Charlotte M Deane. “How repertoire data are changing antibody science.” The Journal of biological chemistry vol. 295,29 (2020): 9823-9837. doi:10.1074/jbc.REV120.010181 抗體呈 Y 字型結構,由兩條相同的重鏈(Heavy chains)與輕鏈(Light chains)組成。結構上可分為負責結合抗原的 Fab 片段(手臂)與負責啟動免疫反應的 Fc 幹體(Stem)。 在分子層次,抗體由以下關鍵區域構成:
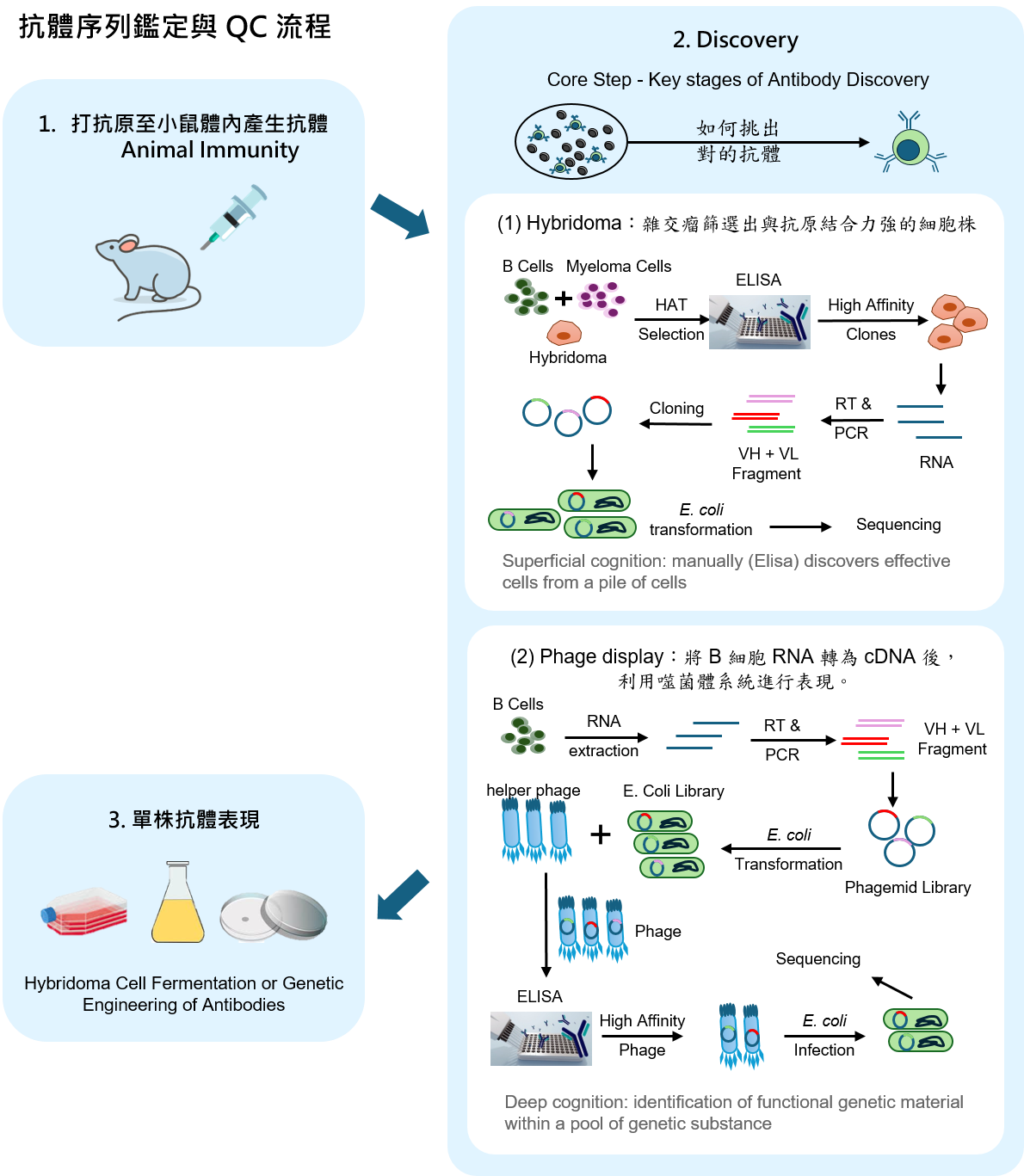
CDRs 的高度多樣性賦予抗體識別萬種抗原的能力,也是抗體工程 (Antibody Engineering) 的核心目標。透過改造 CDRs 的胺基酸序列,研究人員可開發針對新目標的單株抗體,廣泛應用於癌症與傳染病治療。 抗體開發有哪些步驟? 不論是透過 雜交瘤技術(Hybridoma technology) 篩選出高親和力的細胞株,或是經由噬菌體展示技術(Phage display)進行數輪淘選(Panning)所富集的純株,最終皆須進行抗體定序(Antibody sequencing),以確認其 CDRs 序列及框架區(Framework regions)是否發生非預期的突變。 雖然雜交瘤系統可直接對 RT-PCR 產物進行定序,但若要精確評估細胞株的單株純度(Clonal purity),或鑑定噬菌體所攜帶的抗體基因,標準作法仍須經由 E. coli transformation(大腸桿菌轉型) 進行克隆化,隨後抽提質體(Plasmids)以獲取高質量的 DNA 序列資訊。最終,這些海量的序列定序,皆需要高效率定序(High-throughput sequencing)來加速抗體研發的過程。
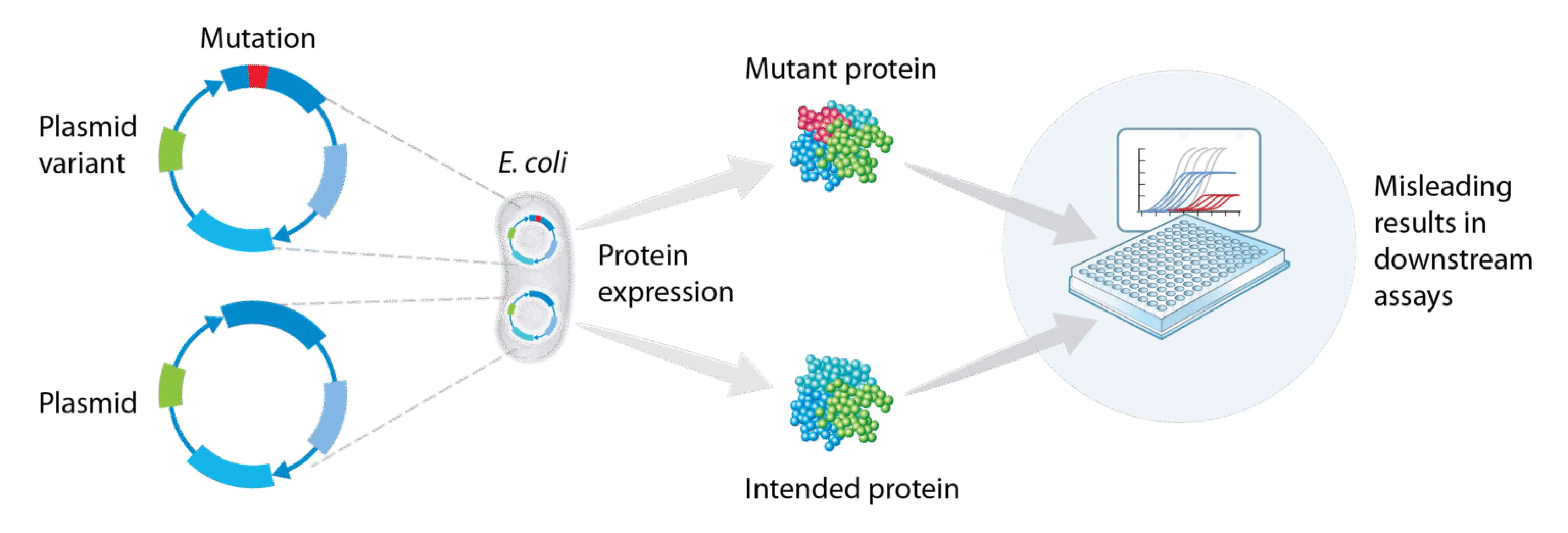
次世代定序 (NGS) 在治療性抗體開發的各個階段(從發現、工程設計到生產)都扮演著至關重要的角色。它能夠識別高親和力、高特異性的候選DNA片段,優化表現系統,並進行品質控制,以維持其遺傳完整性、一致性與安全性。抗體開發中的一個重要考量是確保單株性 (Clonality),特別是在使用細菌表現系統時,co-transformation(圖 1)就會引入變異性。
圖1. 單個細菌在transformation的過程中,可以容納多個質體,當有突變點的質體也包含其中的時候,會嚴重影響下游應用的結果。
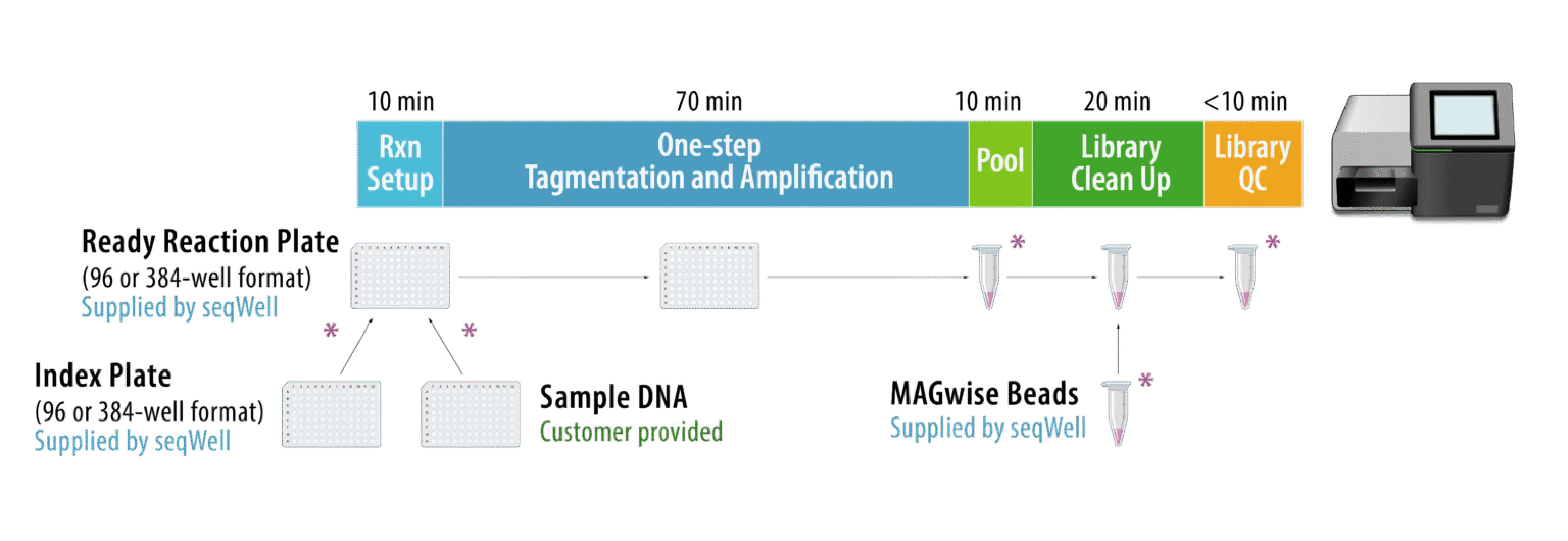
隨著定序技術的演進,若需要具備大規模檢測污染質體的能力,就需要高靈敏度結合高通量的解決方案。NGS 可以幫助解決單株性疑慮,在不造成抗體開發過程瓶頸的情況下,提供對序列準確性的信心。 由於抗體開發流程中 Synthetic construct 的使用規模龐大,定序靈敏度與通量都是關鍵考量因素。建庫(Library prep)方法的選擇會極大影響 NGS 數據生成的可靠性與整體通量,但這一點常被忽視。透過採用高性能及輕鬆同時操作大量樣本的建庫流程,NGS 能夠在確保序列準確性與抗體純度的基準下達到高通量及高靈敏度。 seqWell ExpressPlex™ 2.0 單步驟建庫方案 採用優化的新一代 transposase TnX ,可大幅度降低序列的偏差,並提高序列覆蓋的均勻性。其輕鬆的操作流程(圖2)適用於大量的 Plasmids 及 Amplicons 等 Synthetic construct 定序。
圖2. ExpressPlex 2.0 文庫預備套組利用專有的酶混合物,在單一反應中完成輸入 DNA 的接頭標記(Indexing)與文庫擴增。從質體或擴增子開始,僅需 100 分鐘(其中人工操作時間 30 分鐘)即可完成 96 甚至 384 個樣本的定序準備 (包含上機前 QC)。 ExpressPlex 2.0 展示了超高通量的擴展性,支持多達 6,144 個 Indexes、384 孔盤操作,在自動化設備的流程,只需要 2.5 小時,就能完成 1536 個樣本建庫。 相比之下,他牌 Tn5 轉位酶的工作流顯著更複雜,且對自動化不夠友善。處理 96 個樣本通常需要 3 到 6 小時(視產品而定)。這些差異代表了構建體篩選中的效率與通量限制。
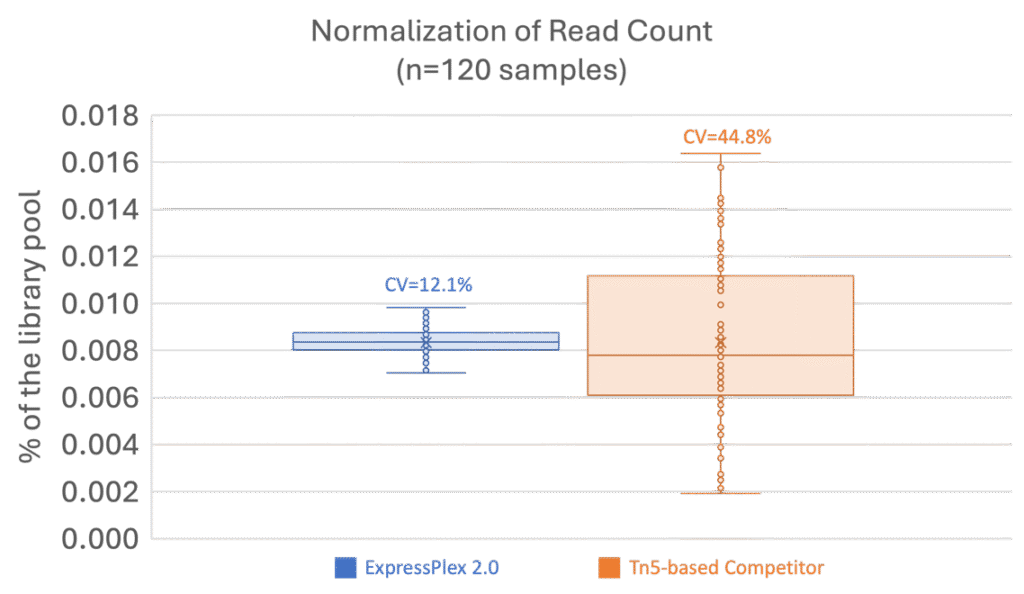
ExpressPlex 2.0 套組將片段化、條碼標記和擴增整合在單一反應中,將人工操作時間縮短至 30 分鐘內。內置的自動校正(Auto-normalization) 功能讓使用者無需手動調整樣本的輸入或輸出濃度。該工作流生成的每個樣本定序讀取數(Read counts)分佈非常集中 (圖3),極大地減輕了高多工定序前的 QC 負擔。
圖3. ExpressPlex 2.0(藍色)在 120 個樣本中實現了更一致的讀取數(變異係數 C.V. 為 12.1%),而他牌(橘色)在相同樣本量下的 C.V. 為 44.8%
在使用細菌宿主的工作流中,單株性問題尤為突出,因為多個質體的 co-transformation 是可能會發生,導致污染。 為了模擬質體共轉化,seqWell 設計了一組 5 個具有單鹼基突變(包括插入、缺失和替換)的質體(圖4)。
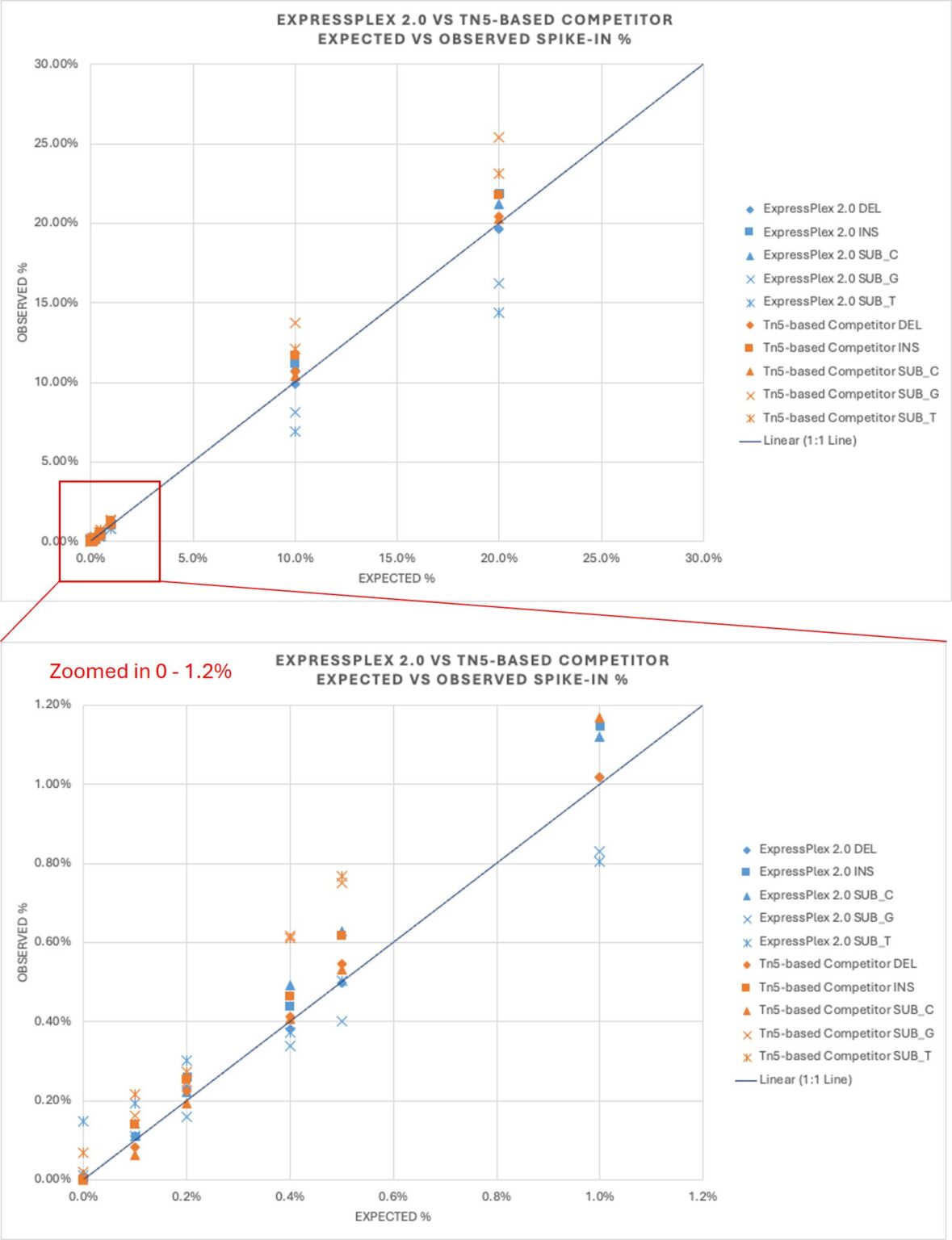
圖4. 設計具有單鹼基突變的質體,包括:A 變 C、A 變 G、A 變 T、單鹼基缺失及單鹼基插入。 接著,研究人員將攜帶單鹼基突變的質體以 8 個不同比例摻入(Spike-in)背景控制質體中:0%(對照組)、0.1%、0.2%、0.4%、0.5%、1%、10% 和 20%,以評估 ExpressPlex 2.0 檢測共轉化的能力。 實驗同時使用他牌的 Tn5 套組處理相同樣本,並在 Illumina NextSeq 2000 上進行定序。行業公認的靈敏度標準設定為 0.5% 的共轉化變異量。即使在低於 1% 的低比例摻入情況下,ExpressPlex 2.0 也能準確追蹤預期的變異百分比(圖5)。
圖 5. 準確量化低於 1% 的污染質體,證明了 ExpressPlex 2.0 在質體純度品質控制方面的強大能力。 總結 單個細菌內非預期存在多個質體會導致錯誤的結果。藉由靈敏、高通量的建庫流程,研究人員可以增強檢測和量化低水平序列變異的能力。 ExpressPlex 2.0 文庫預備套組的優勢
▲ 前往了解更多關於 ExpressPlex 細節,或洽詢 伯森生技 獲得完整產品資訊。 ▲ 查看原文章 [seqWell Blog] Antibody Development: Addressing Plasmid Impurity。 您可透過下方連結瀏覽更多相關資訊: |
|||||||

伯森生物科技(股)公司 Blossom Biotechnologies, Inc.
網址 www.blossombio.com 客服 0800-059668
[ 📝 線上留言諮詢
] [ ☎ 伯森業務專員聯絡資訊
]
![]()
![]()